
Empirical Exercise 4
In this exercise, we’re going to be replicating the difference-in-differences analysis from Does a ban on informal health providers save lives? Evidence from Malawi by Professor Susan Godlonton and Dr. Edward Okeke. Table 5, which we will replicate, summarizes the impact of Malawi’s 2007 ban on the use of traditional birth attendants (TBAs) on birth outcomes, including both the use of formal sector providers and neonatal mortality.
Getting Started
The do file needed for this activity is here: E4-questions.do.
The data set E4-GodlontonOkeke-data.dta is available on glow. It contains information (from the 2010 Malawi Demographic and Health Survey) on 19,680 live births between July 2005 and September 2010. Each observartion represents a birth. Download the data, and then create a do file that opens the data set in Stata. Our standard code for starting a do file will look something like:
/* Replicating Table 5 from Godlonton & Okeke (2015) */
// PRELIMINARIES
clear all
set more off
set scheme s1mono
set seed 123456
cd "C:\mypath\E4-DD2"
use "C:\mypath\E4-DD2\E5-GodlontonOkeke-data.dta"
Generating the Variables Needed for Analysis
To implement difference-in-differences, we need:
- a dummy variable for the post treatment period,
- a dummy variable for the treatment group, and
- an interaction between the two
The
postvariable is already present in the data set. What is the mean of thepostvariable? What fraction of the observations in the data set occur in the post-treatment period?
The time variable indicates the month and year in which a birth took place. If you type the command
desc time you’ll see the following output:

Notice that the time variable is formatted in Stata’s date format: it is stored as a number,
but appears as a month and year when you describe or tabulate it.
Use the command
tab time post
to see how Professor Godlonton and Dr. Okeke define the post-treatment time period in their analysis. What is the first treated month?
Next we need to define an indicator for the treatment group. Professor Godlonton and Dr. Okeke define the treatment group as DHS clusters (i.e. communities) that were at or above the 75th percentile in terms of use of TBAs prior to the ban. Data on use of TBAs comes from responses to the question below:

Responses have been converted into a set of different variables representing the different
types of attendants who might have been present at the birth. Tabulate (using the tab command)
the m3g variable, which indicates whether a woman indicated that a TBA was present at a birth. What pattern of responses do you observe?
We want to generate a dummy variable that is equal to one if a TBA was present at a particular birth, equal to zero if a TBA was not present, and equal to missing if a woman did not answer the question about TBAs.
There are several different ways to do this in Stata. One
is to use the recode command:
recode m3g (9=.), gen(tba)
This generates a new variable, tba, that is the same as the m3g variable except that tba is equal to missing for all
observations where m3g is equal to 9. (It is usually better to generate a new variable
instead of modifying the variables in your raw data set, because you don’t want to make
mistakes that you cannot undo.) Confirm that your new variable, tba, is a dummy variable. Use the command
tab tba, m
to tabulate the observed values of tba (the , m option tells
Stata to tabulate the number of missing values in addition to the other values).
We want to generate a treatment dummy - an indicator for DHS clusters where use of TBAs was at or above
the 75th percentile prior to the ban. How should we do it? The variable dhsclust is an ID number
for each DHS cluster. How many clusters are there in the data set?
We can use the egen command
to generate a variable equal to the mean of another variable, and we can use egen with the bysort option
to generate a variable equal to the mean within different groups:
bysort dhsclust: egen meantba = mean(tba)
However, this tells us the mean use of TBAs within a DHS cluster over the entire sample period, but we only want a measure of the mean in the pre-ban period. How can we modify the code above to calculate the level of TBA use prior to the ban?
Now summarize your meantba variable using the , detail or , d option after the sum command
so that you can calculate the 75th percentil of TBA use in the pre-ban period. As we’ve seen in earlier
exercises, you can use the return list command after summarize to see which locals are saved when
you run the summarize command in Stata:
sum meantba, d
return list
local cutoff = r(p75)
The last line in the code above (when implemented immediately after the sum meantba, d command,
stores a local macro equal to the 75th percentile of the variable meantba. Now we need to create a new variable high_exposure that is an
indicator for DHS clusters where the level of TBA use prior to the ban exceeded the cutoff we just
calculated. How might you go about doing this?
Remember: meantba is only non-missing for births (ie observations) in the pre-treatment period.
If you type
gen high_exposure = meantba>=`cutoff' if tba!=.
you will end up setting high_exposure to one for all post-treatment observations. You
don’t want to do that! Modify the code so that you only define high_exposure for births
where the meantba variable is non-missing.
Of course, now we have a small problem: you’ve successfully defined a high_exposure
variable that is an indicator for DHS clusters where the level of TBA use was at or above the
75th percentile in the pre-ban period, but your treatment variable is missing for all births
in the post-ban period. This issue comes up a lot. Here are three lines of
code that will fix it:
bys dhsclust: egen maxtreat = max(high_exposure)
replace high_exposure = maxtreat if high_exposure==. & post==1 & tba!=.
drop maxtreat
Tabulate your high_exposure variable to make sure that it is only missing for observations
with the tba variable missing. What is the mean of high_exposure?
The last variable we need to conduct difference-in-differences analysis is an interaction between
our treatment variable, high_exposure, and the post variable. Generate such a variable.
I suggest calling it highxpost. Now you are ready to run a regression.
Replicating One Coefficient
Now you have the variables you need to run a 2x2 difference-in-differences analysis
on the impact of Malawi’s ban on TBAs on their use. Do this. How does the coefficient of interest
(on the interaction between post and high_exposure) compare to the results reported in
Panel A of Table 5 in Godlonton and Okeke (2015), shown below? (Right click on the table to open it
in a new tab so that you can actually read it.)
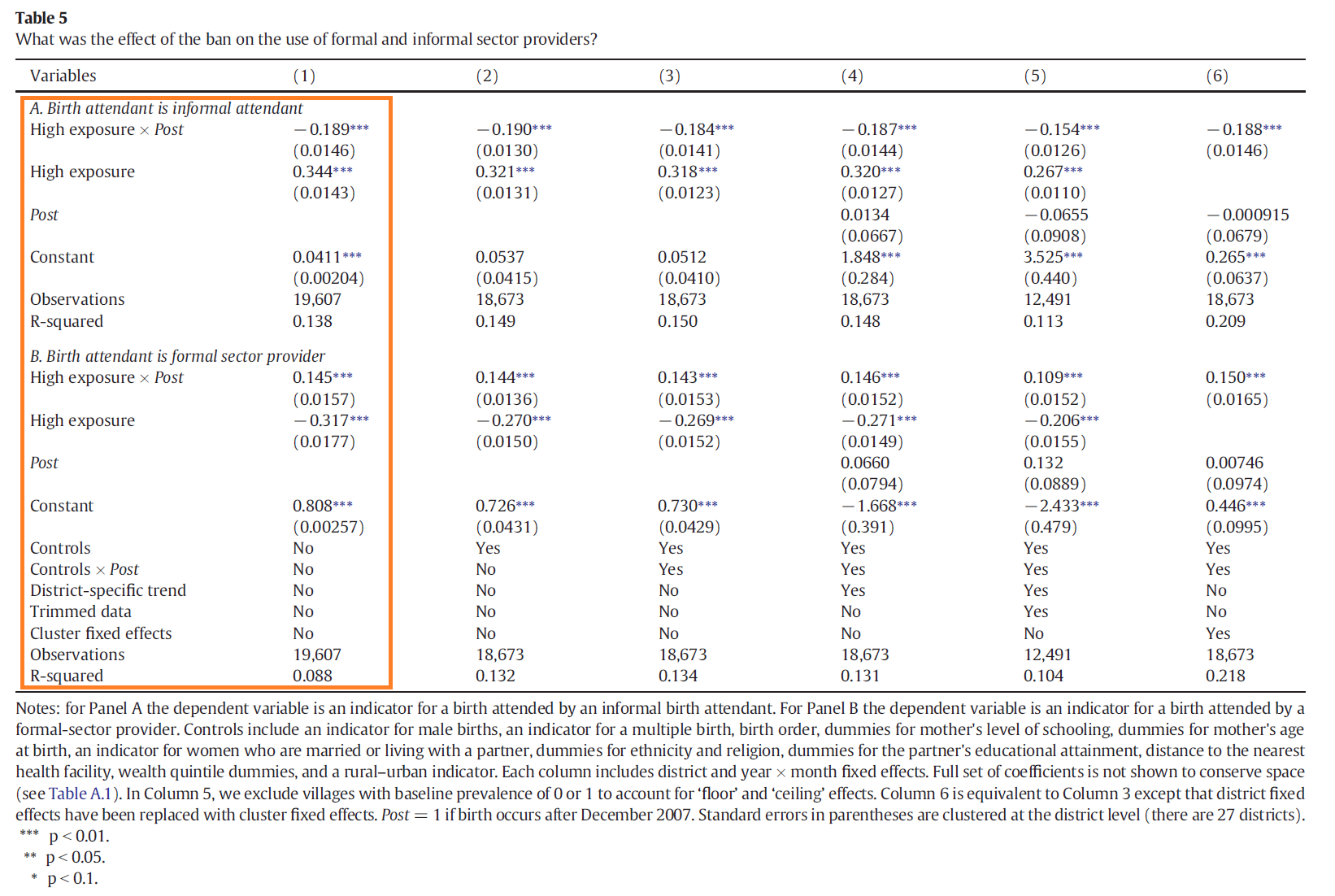
You are using the same data set as Professor Godlonton and Dr. Okeke, so you should be able to replicate their coefficient estimates and standard errors exactly. Have you done it? If not, look closely at the coefficients that they report and read their table notes carefully. Try to figure out what you need to change to replicate their exact results. Once you’ve done that (Congratulations! You replicated a table in a published paper!), move on to the rest of the empirical exercise.
(Hint: if you want Stata to include fixed effects for, for example, time periods, you add the code i.time like it is an additional variable in your regression.)
Empirical Exercise
In the remainder of this exercise, we will be estimating the impact of Malawi’s ban on traditional birth attendants
on the use of formal sector providers (aka skilled birth attendants or SBAs). The variable sba is an indicator
for use of (wait for it) an SBA. Estimates of the impact of the TBA ban on use of SBAs are reported in Panel B of
Table 5 in Godlonton and Okeke (2015).
Before we begin, we’re going to set up an Excel file where we can record our results. Our coefficient of interest is the highxpost variable, which is the interaction between the post dummy and the high_exposure dummy. Our regression table will only record this coefficient. Add the following Stata code to your do file to set up your Excel file that will receive your coefficient estimates.
putexcel set E4-DD-table.xlsx, replace
putexcel B1="(1)", hcenter bold border(top)
putexcel C1="(2)", hcenter bold border(top)
putexcel A2="High Exposure x Post", bold
putexcel A4="Observations", bold border(bottom)
Make sure you understand the code above before proceeding with the exercise.
Question 1
Test the hypothesis that the proportion of women giving birth in the presence of a skilled birth attendant increased after Malawi introduced the ban on TBAs. What is the t-statistic associated with this hypothesis test?
Question 2
Estimate a simple 2x2 difference-in-differences specification to measure the impact of Malawi’s TBA ban on the use of SBAs. Your regression should include the post dummy, the high-exposure (i.e. treatment) dummy, and the highxpost interaction term (and no other independent variables). What is the estimated coefficient of interest (ie the coefficient on highxpost)?
Question 3
To export our regression coefficients to Excel, we first need to save our regression results to a matrix in Stata. We will do this with the command
matrix V = r(table)
The r(table) refers to Stata’s default way of storing regression results; the command defines a matrix V containing the regression results. Type matrix list V into the command window to see this matrix.
You can see that the matrix is 9 rows tall. The number of columns is one plus the number of variables included in our regression. The first row contains the coefficient estimates, the second row contains the standard errors, the third row contains the t-statistics, and the fourth row contains the p-values.
If we estimated our regression using the command
reg sba post high_exp highxpost
then our coefficient of interest is the third variable in the regression. This means that the coefficient estimate, standard error, etc. are stored in the third column of the matrix V. To export the coefficient estimate to cell B2 in Excel, we can use the commands:
local my_coef = round(V[1,3],0.01)
putexcel B2 = "`my_coef'", hcenter
where V[1,3] refers to the cell of the matrix V in the first column and the third row. Implement this code, making sure that you are successfully exporting your regression coefficient of interest.
Question 4
Now write the standard error associated with the regression coefficient on highxpost to cell B3 in your Excel file.
Question 5
Use the code below (after your regression) to export the number of observations to cell B4 in your Excel file:
putexcel B4 = `e(N)'
Question 6
Now re-run your diff-in-diff estimation replacing the post variable with time fixed effects. What is the estimated coefficient on highxpost now? Write your coefficient on highxpost, the associated standard error, and the number of observations to Column C in your Excel file.
Question 7
As we saw above, Professor Godlonton and Dr. Okeke also include district fixed effects. Re-run your diff-in-diff estimation including these as well. What is the estimated coefficient on highxpost now? Write your coefficient on highxpost, the associated standard error, and the number of observations to Column D in your Excel file.
At this point, you (should) have successfully replicated the result from Godlonton and Okeke (2015). As you saw, the coeffcient on the highxpost (the diff-in-diff estimate of the treatment effect) was extremely similar in specifications with and without fixed effects.
More Fun with Stata
Professor Godlonton and Dr. Okeke test common trends directly by generating a time trend variable that they interact with treatment. Their results are presented in Table 2 in their paper, which appears below:
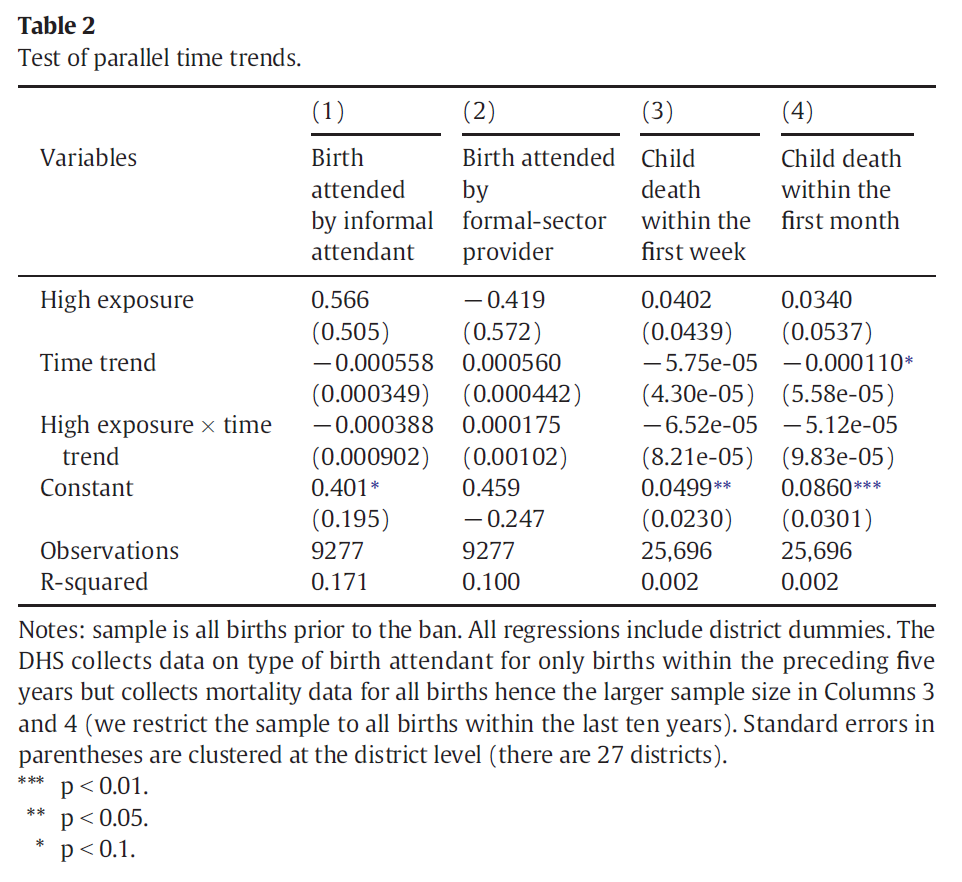
We are primarily interested in the interaction between our treatment variable,
high_exposure, and the time trend: if this variable is statistically significant,
it indicates that the treatment and comparison groups were on different trajectories
prior to the program.
To replicate these results, we need to generate a time trend variable. The data set
contains the variable time; it indicates the the month and year in which a birth
took place. However, time is formatted in Stata’s date-time format, which even
economics professors can never remember how to use. Fortunately, we can use
the egen command to create a trend variable after we sort the data by date:
sort time
egen trend = group(time) if post==0
The egen option group creates a variable indicating the different groups (or values)
of the time variable. So, in this data set, the egen command will generate a group variable as
follows:
| time | trend |
|---|---|
| Jul05 | 1 |
| Jul05 | 1 |
| Jul05 | 1 |
| Aug05 | 2 |
| Aug05 | 2 |
| Oct05 | 3 |
| Oct05 | 3 |
Notice that egen is just counting off the groups: there are no observations
from September of 2005, so October 2005 is the third group (ie the egen command
is not telling us how many months have passed since the start of the data set). In this case,
you can tab time and see that there aren’t any missing months, so the trend variable
does also tell us how many months an observation is from the earliest observations in
the data set - but that is because of the particular structure of this data set. (Also,
remember that you have to sort your data before using the egen command with the group
option.)
Once you’ve generated the trend variable, you need to interact it with high_exposure
(the treatment dummy). Then you can regress an outcome like tba on the high_exposure
variable, the trend variable, and the interaction between them. The table notes
above also indicate that Professor Godlonton and Dr. Okeke include district fixed effects;
you can add these by adding i.district to your regression command.
Do you get the same results as the authors? Specifically, do the coefficient and
standard error on the variable highxtrend match up?