
Empirical Exercise 8
In this exercise, we’ll be using data from the paper The Miracle of Microfinance? Evidence from a Randomized Evaluation by Abhijit Banerjee, Esther Duflo, Rachel Glennerster, and Cynthia Kinnan. The paper reports the results of one of the first randomized evaluations of a microcredit intervention. The authors worked with an Indian MFI (microfinance institution) called Spandana that was expanding into the city of Hyderabad. Spandana identified 104 neighborhoods where it would be willing to open branches. They couldn’t open branches in all the neighborhoods simultaneously, so they worked with the researchers to assign half of them to a treatment group where branches would be opened immediately. Spandana held off on opening branches in the control neighborhoods until after the study.
Before getting started, take a look at this J-PAL policy brief on the impacts of microfinance. We’ll be using a small slice of the data from the paper by Banerjee, Duflo, Glennerster, and Kinnan to explore the use of instrumental variables techniques to estimate impacts of treatment on the treated - and to think about when such methods are appropriate.
Getting Started
Before you get started, you need to open Stata and install the commands estout and eret2. Use the findit command in Stata to
locate the links to install these user-written programs.
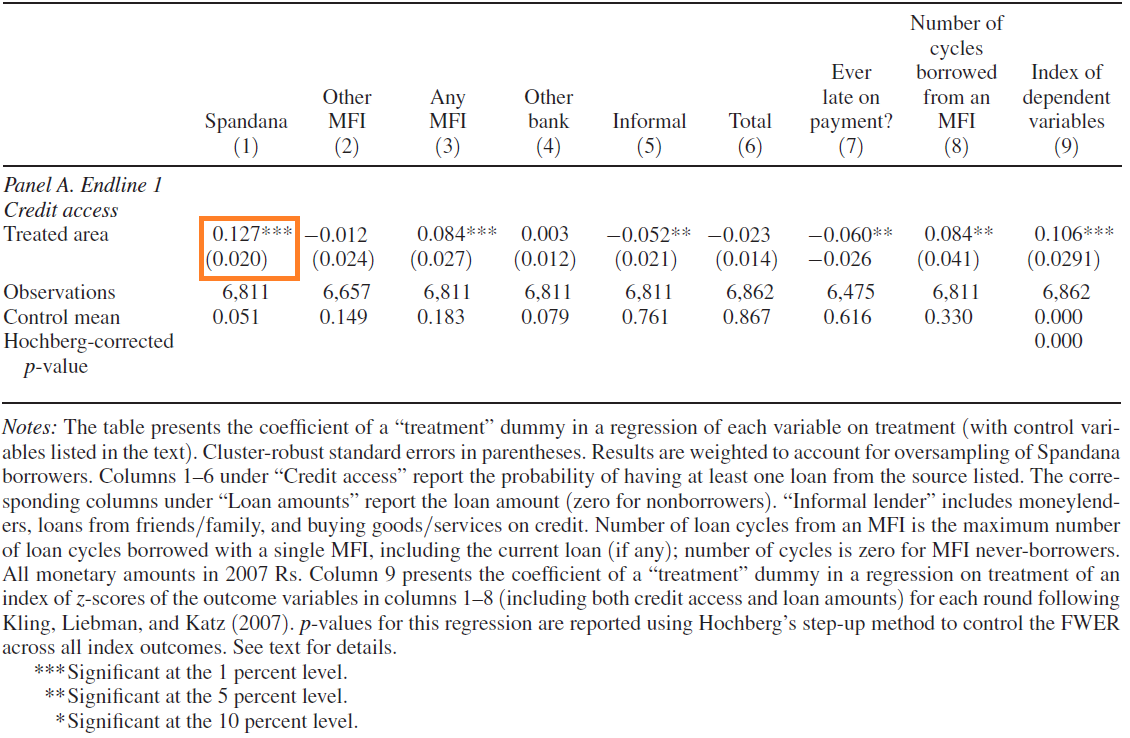
Now open this do file in your do file editor. The do file opens a data set containing information on 6,863 households in treatment and control neighborhoods in Hyderabad; these households were randomly sampled form the local population, so not all of them will have chosen to take out loans from an MFI.
The do file
starts with Banerjee et al’s replication code to recreate Table 2. After you run this code, you will have a file called
Table2.txt saved in your local folder. Table2.txt will contain the same results reported in Panel A of the paper. We’re
going to focus on the first column, which reports the estimated impact of treatment (having a Spandana branch open in your
neighborhood) on the likelihood of taking out a Spandana micrloan:
The replication code shows you some of the many tricks economists use when writing do files: storing a set of controls
as a local or global macro that is included in each specification, writing a foreach loop to run the same regression for a number of
different outcome variables, using regression weights so that a sample is representative of a population of interest,
and saving the regression results in a text file using the estout command. You don’t need
to understand every line, but these techniques will help you write clearer do files faster.
The Impacts of Treatment on the Treated
We’re going to focus on a simpler specification in this exercise. The last line of the do file runs the regression
reg spandana_1 treatment, cluster(areaid)
Your results should be fairly close to Column 1 of Table 2, but not identical (because we’re not including controls, or reweighting observations). The results indicate that assignment to treatment leads to a statistically significant increase in the likelihood of taking out a microloan from Spandana. How large is this estimated treatment effect? What does this coefficient tell us about take-up of the intervention in this evaluation?
Now, run a new regression to estimate the impacts of treatment (access to a Spandana branch in your neighborhood) on the
bizprofit_1 variable, which reports a household’s total profits from their small businesses (which we often refer to
as microenterprises - because they are typically very small). What is the estimated
treatment effect on microenterprise profits? Is the estimated treatment effect statstically significant? What are the upper and lower
bounds on the 95 percent confidence interval?
Now, suppose you thought that the impacts of treatment (Spandana branches) on microenterprise profits could only be the result of borrowing from Spandana. How would you use the two coefficients that you just estimated to calculate the estimated impact of treatment on the treated? What is the estimated TOT effect?
Now calculate the estimated TOT effect using instrumental variables:
ivregress 2sls bizprofit_1 (spandana_1 = treatment), ///
cluster(areaid)
Did you get the coefficient that you expected? How large is the confidence interval?
When we use instrumental variables to estimated the impact of treatment on the treated, we are assuming that treatment has no impacts whatsoever on those who do not take up treatment. Does that make sense in the context of microfinance? Why or why not?
Empirical Exercise
In the remainder of this exercise, we’re going to focus our analysis on individuals and households that were already operating a microenterprise before Spandana started expanding its operations in Hyderabad. Banerjee, Duflo, Glennerster, and Kinnan find that these households seem to have benefited the most from access to microcredit.
To make your life easier, drop all the observations for whom any_old_biz==0. This should leave you with
1,612 observations in your data set. Now, use your data to answer the following questions.
- Estimate the impact of treatment on the likelihood of taking a loan from Spandana (the variable
spandana_1) in this restricted sample. What is the estimated coefficient ontreatment? Be sure to cluster byareaid, as you did in your earlier regressions. - Is the impact of treatment on taking out a Spandana loan larger or smaller for those with an existing business, relative to those who did not already have a microenterprise?
- In the restricted sample of households with a pre-existing microenterprise (ie those with
any_old_biz==1), what is the estimated impact of treatment on microenterprise profits (the variablebizprofit_1)? - What is the p-value associated with this coefficient?
- Using only this information, what is the estimated impact of treatment on the treated (if we assume that access to a Spandana branch only impacts those who take out loans)?
- Now use intstrumental variables to calculate the estimated impact of treatment on the treated. What is the estimated TOT effect?
- Is the estimated TOT effect statistically significant? What is the p-value?
- In 1-2 sentences, explain why this estimated impact of TOT should be treated with caution? Which IV assumptions may not hold in this context?