
Empirical Exercise 4
This is the empirical exercise associated with our first module on difference-in-differences estimation. In this exercise, we’re going to analyze data from Ignaz Semmelweis’ handwashing intervention in the maternity hospital in Vienna. The data come from Semmelweis’ (1861) book, and some helpful person put them on Wikipedia.
Getting Started
To get started, create a directory for this exercise, and then save
Semmelweis data to your directory.
The data set is in excel, so we’ll be using Stata’s import excel command to read them into Stata.
To make sure that you have downloaded the data correctly, open Stata, change the directory to the
new folder you created for this excercise (using the cd command), and then use the ls command to
list the contents of the directory. You should see the excel file containing Semmelweis’ data on maternal mortality
listed in your directory.
We’ll be making graphs in this exercise. Before doing this, you should install Stata’s blindschemes
package if you have not already. Type the command findit blindschemes to look for the package on the web.
You should see a window that looks like this (minus the red arrow):
Click the first link (where the arrow is pointing) and follow the instructions to install the
blindschemes package. This will allow you to access the colors of the
Okabe-Ito colorblind-friendly palette to make
elegant data visualizations.
Warm-Up Activity
The warm-up activity is also available as a do file.
In this activity, we’ll look at data from Vienna’s two clinics: the Doctor’s Wing which was staffed by doctors and trainee doctors (who handled cadavers as part of their training) and the Midwive’s Wing which was staffed by (unsurprisingly) midwives (who did not handle cadavers). Use the following Stata code to read in and prep your data:
clear all
set scheme s1mono
set more off
set seed 314159
version 16.1
** change working directory
cd "C:\Users\pj\Dropbox\econ379-2021\exercises\E4-DD1"
** load the data from the course website
import excel using E4-Semmelweis1861-data.xlsx, ///
sheet("ViennaBothClinics") first
** label the variables
label var Births1 "Births in Doctors Wing"
label var Deaths1 "Deaths in Doctors Wing"
label var Rate1 "Mortality Doctors Wing"
label var Births2 "Births in Midwives Wing"
label var Deaths2 "Deaths in Midwives Wing"
label var Rate2 "Mortality in Midwives Wing"
We start with the usual preliminaries (setting the seed, etc.),
the we use the import excel command to read in the data. Notice
that we use the sheet() option to specify which sheet we want to use
and the first option to tell Stata that the first row in our data set
is variable names rather than data values. The last thing we do is
use the label var command to assign each variable a descriptive label
(that would appear, for example, if we listed the variables and their
descriptions using the desc command).
Make sure you understand every line in the code above before proceeding to the next part of the activity.
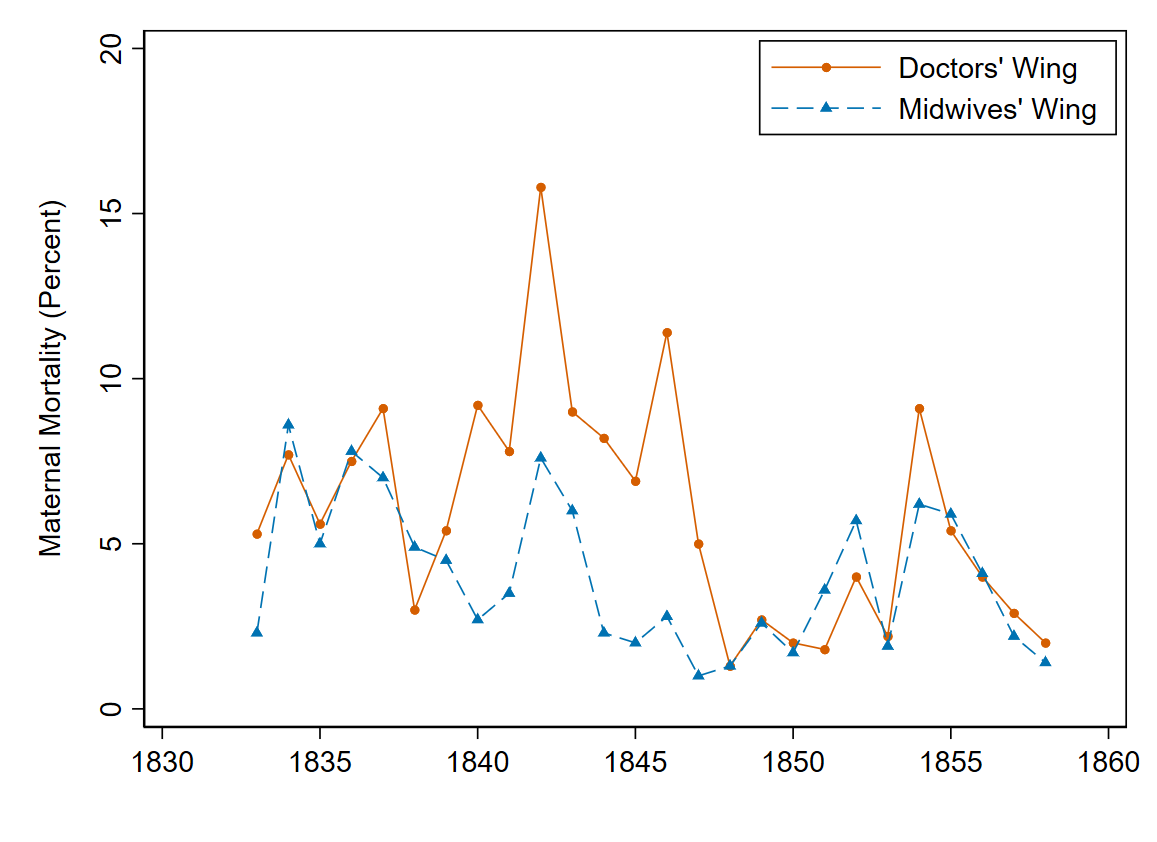
Now use the code below to plot the maternal mortality rate in the two wings
of Vienna’s maternity hospital between 1833 and 1858. We’re using Stata’s
twoway command, which allows you to visualize the relationship between two
variables in a number of different ways (eg as a bar graph, a scatter plot, etc).
twoway (connected Rate1 Year, color(vermillion) msymbol(o) msize(small) lw(thin)) ///
(connected Rate2 Year, color(sea) msymbol(t) msize(small) lw(thin)), ///
ylabel(0(5)20) ytitle("Maternal Mortality (Percent)" " ") ///
xlabel(1830(5)1860) xtitle(" ") ///
legend(label(1 "Doctors' Wing") label(2 "Midwives' Wing") col(1) ring(0) pos(2))
graph export vienna-by-wing-fig1.png, replace
There are several things to notice about this code. First, we are breaking a long command
into multiple lines using /// at the end of each line. Second, we’re graphing
two different dependent variables: the maternal mortality rate in the doctors’ wing and
the maternal mortality rate in the midwives’ wing.
The twoway command allows you to overlay multiple plots on a single graph using the syntax
twoway (type1 y1 x1, options) (type2 y2 x2, options)
where type1 is the type of twoway graph (eg a scatter plot), y1 is your first
dependent variable, x1 is your first independent variable, etc. When we overlay plots
in this way, we usually use the same x variable in both plots - but not always.
Note that we put a comma after our last plot, before we start listing options (like the plot title)
that pertain to the entire graph. The ylabel option allows us to specify the start and endpoints
for the y-axis, and the distance between tick marks and labels. The ytitle option
allows us to specify a title (or label) for the entire y-axis. The legend option
allows us to list which of the different twoway plots should be listed in the legen, and also
how many columns the legend should contain and where it should be positioned on our graph.
More information about using the twoway command is available if you type help twoway.
Finally, we use the graph export command to save our graph as a .png file. You can
also save your graph as a pdf. Your graph should look like this:
Warm-Up Activity Questions
- Use the
listcommand to list the the notes contained in the data set by year:list Year Note. In what year did the Vienna Hospital move to the system where only midwives worked in the second clinic? Drop the observations (years) before this happened using thedropcommand. - Now make a new version of your graph that plots this restricted data set. You’d want to modify the
xlabel(1830(5)1860part of your code so that you only show a narrow window around the data you are plotting. Add a line showing when the hospital instituted the handwashing policy by inserting the textxline(1847)somewhere after the comma in yourtwowaycommand. Now you’ve made a graph of the first ever diff-in-diff. - Generate a
postvariable equal to one for years after the handwashing policy wash implemented (and zero otherwise). What is the mean maternal mortality rate in the doctors’ wing prior to the implementation of the handwashing policy? (Hint: you can use Stata’ssum- akasummarize- command here. Remember that you can always use thereturn listcommand after a command likesummarizeto see what statistics the summarize command stored in Stata’s short-term memory as locals.) - We can calculate the standard error of the mean by hand by taking the standard deviation (reported by the
sumcommand) and dividing it by the square root of the number of observartions. (Hint: you can do this more or less by hand by looking at the output from thesumcommand, but you can also use the fact that Stata saves the output of thesumcommand as local macros and use the commanddisplay r(sd)/sqrt(r(N))immediately aftersumto have Stata calculate the standard error of the mean for you from the standard deviation - saved as the localr(sd)- and the number of observations - saved as the localr(N).) What is the standard error of the mean maternal mortality rate in the doctors’ wing prior to Semmelweis’ handwashing intervention? - You can also get the standard error of a mean using Stata
ci meancommand (thecicommand gives you confidence intervals for different summary statistics, andmeanis only one of the options). Use the commandci mean Rate1 if post==0to confirm that your standard error calculation (above) is correct. What is the upper bound of the 95 percent confidence interval for the mean ofRate1in the years prior to the handwashing intervention? - What is the mean postpartum mortality rate in the Doctors’ Wing after the implementation of the handwashing intervention?
- What is the mean postpartum mortality rate in the Midwives’ Wing before the implementation of the handwashing intervention?
- What is the mean postpartum mortality rate in the Midwives’ Wing after the implementation of the handwashing intervention?
- Use these four means to calculate the difference-in-differences estimate of the impact of (doctors’) handwashing after handling cadavers on postpartum mortality. What is the estimated treatment effect?
- If we assume that the four means are independent random variables, we can calculate the standard error associated with the difference-in-differences estimate of the treatment effect. What is this standard error?
- We can also calculate the difference-in-differences estimate of the impact of Semmelweis’ handwashing intervention by calculating the difference in the mortality rate between the Doctors’ Wing and the Midwives’ Wing, and testing whether this difference declines after the start of the intervention. Do this, and estimate the treatment effect using a univariate linear regression. What is the estimated coefficient on the
postdummy?
Homework Activity
The empirical exercise is also available as a do file.
Now we’re going to look at the data from the main maternity hospitals in Vienna (treatment) and Dublin (control). We’ve already examined Ignaz Semmelweis’ handwashing intervention. Now, we will test whether the introduction of the pathological anatomy program in Vienna (which saw medical students practicing with cadavers) had an impact on the rate of postpartum mortality in Vienna.
Create a do file that starts with all the usual preliminaries and then uses the code below to read in data on mortality at the maternity hospitals in Vienna and Dublin.
import excel using E4-Semmelweis1861-data.xlsx, ///
sheet("ViennaTotals") first
sort Year
save ViennaData.dta, replace
clear
import excel using E4-Semmelweis1861-data.xlsx, ///
sheet("DublinTotals") first
sort Year
save DublinData.dta, replace
The data is stored in two separate sheets in the excel file,
so we need to read in each sheet separately and save them in Stata format. We include the sort command so that each data set is
sorted by year (this will be important when we want to merge them together).
The next step is to merge the two data sets. Right now, we have two different data sets, each of which reports the values of different variables in different years. In each data set, each observation represents a different year. Merging combines them into a single data set which still has one observation per year; however, the new data set contains all the other variables in either of the original data sets.
Here is an example. Suppose I had two data sets. Suppose the first one looked like this:
| year | days |
|---|---|
| 2010 | 365 |
| 2011 | 365 |
| 2012 | 366 |
| 2013 | 365 |
| 2014 | 365 |
And the second one looked like this:
| year | months |
|---|---|
| 2010 | 12 |
| 2011 | 12 |
| 2012 | 12 |
| 2013 | 12 |
| 2014 | 12 |
After merging these data sets by year we’d have a combined data set that looked like this:
| year | days | months |
|---|---|---|
| 2010 | 365 | 12 |
| 2011 | 365 | 12 |
| 2012 | 366 | 12 |
| 2013 | 365 | 12 |
| 2014 | 365 | 12 |
To merge our postpartum mortality data sets in Stata, we use the following code:
clear
use ViennaData.dta
merge 1:1 Year using DublinData.dta
After running the merge command, we’ll see the following output:
Result # of obs.
-----------------------------------------
not matched 0
matched 66 (_merge==3)
-----------------------------------------
You can see that all the observations (ie years) in the data set merged successfully.
In other words, every year in the DublinData.dta data set also appears in the
ViennaData.dta data set. The variable _merge indicates whether a variable
appears in both data sets, or just in the data set that you started with
(the master data) or the data set that you merged in (the using data).
Homework Activity Questions
Now that you’ve merged your data, use the combined data set to answer the following questions about the impact of Vienna’s anatomical training program on postpartum mortality in its teaching hospital.
- Use the command
list Year V_Noteto list the comments about what was happening at the Vienna Hospital in every year. In what year did the “pathological anatomy” program (ie the use of cadavers in anatomy class) begin? - Since we want to look at the impact of the pathological anatomy program, we want to drop observations from 1847 on (after Semmelweis’ handwashing intervention was implemented in Vienna). What is the mean rate of postpartum mortality at the Dublin hospital after dropping those observations?
- Adapt your code from the in-class activity to make a figure showing the evolution of postpartum mortality rates in Vienna and Dublin. You’ll want to change the names of the dependent variables being plotted, the starting and ending years, and the labels on the two lines being graphed. You are also welcome to make additional changes to the code to further modify your graph.
- Generate a variable
postthat is equal to one for years when the pathological anatomy program was active in Vienna. What is the mean of this variable? - What is the mean rate of postpartum mortality in Vienna before the introduction of the pathological anatomy program?
- What is the mean rate of postpartum mortality in Vienna after the introduction of the pathological anatomy program?
- What is the mean rate of postpartum mortality in Dublin before the introduction of the pathological anatomy program?
- What is the mean rate of postpartum mortality in Dublin before the introduction of the pathological anatomy program?
- Use these four means to calculate the difference-in-differences estimate of the impact of Vienna’s pathological anatomy training on postpartum mortality. What is the estimated treatment effect?
- We can also calculate the difference-in-differences estimate of the impact of the pathological anatomy training by first calculating the difference in the mortality rate between the Vienna Hospital and the Dublin Hospital and then testing whether this difference declines after the start of the anatomy training curriculum. Do this, and estimate the treatment effect using a univariate linear regression. What is the estimated regression coefficient associated with the
postvariable? - What is the standard error associated with the
postvariable in the regression above? - Did the introduction of an anatomy training program have a statistically significant impact on postpartum mortality in Vienna? What is the t-statistic associated with the
postvariable in your difference-in-differences specification?